Introduction
- Overview of Apache Kafka:
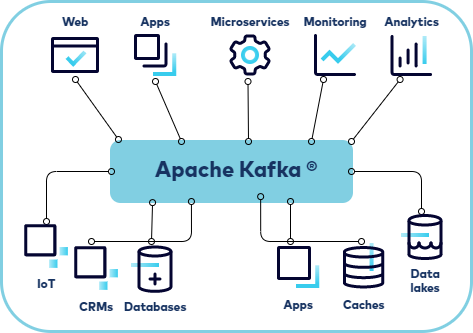
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. - Importance of Real-Time Data Streaming:
Real-time data processing is crucial in various industries like finance, e-commerce, IoT, and telecommunications. Kafka allows companies to handle real-time data efficiently, making it an essential tool for modern data infrastructures.
History and Evolution
- Origins of Kafka:
Kafka was originally developed at LinkedIn by Jay Kreps, Neha Narkhede, and Jun Rao in 2011. It was open-sourced later that year and has since become a leading tool for real-time data streaming. - Kafka’s Growth:
Over the years, Kafka has evolved from a simple messaging queue into a full-fledged event streaming platform, supporting thousands of enterprises worldwide.
Core Concepts
- Producers and Consumers:
Producers are applications that publish (or write) events to Kafka topics. Consumers subscribe to these topics to read and process the events. - Brokers:
Kafka brokers are servers that store data and serve clients (producers and consumers). A Kafka cluster is composed of multiple brokers to provide fault tolerance and scalability. - Topics and Partitions:
Topics are categories to which records are published. Each topic is divided into partitions, allowing Kafka to scale horizontally across multiple servers. - Zookeeper:
Zookeeper is used to manage and coordinate Kafka brokers in a distributed environment. However, Kafka is moving towards a Zookeeper-less architecture with the introduction of KRaft mode.
Kafka Architecture
- Distributed System:
Kafka is designed to be distributed across multiple servers, ensuring fault tolerance and high availability. - Log-Based Storage:
Kafka stores records in a log, which is an append-only sequence of records, enabling efficient storage and retrieval. - Replication:
Kafka replicates data across multiple brokers, ensuring data durability and reliability in case of failures.
Kafka Use Cases
- Real-Time Analytics:
Companies use Kafka to process real-time data streams for analytics, such as tracking user behavior on websites or monitoring financial transactions. - Log Aggregation:
Kafka can aggregate logs from various sources, centralizing log management and enabling real-time monitoring and analysis. - Event Sourcing:
Kafka’s ability to store event logs makes it ideal for event sourcing, where state changes are captured as a sequence of immutable events. - Microservices Communication:
Kafka facilitates communication between microservices by decoupling the production and consumption of messages, making it easier to scale and manage microservices architectures.
Setting Up Kafka
- Installation:
Download Kafka from the Apache Kafka website and extract it to your desired directory. Start the Zookeeper server, then start the Kafka server.
Node.js Example: Producing and Consuming Messages
Step 1: Install KafkaJS
npm install kafkajs
Step 2: Create a Kafka Topic Using Node.js
const { Kafka } = require('kafkajs');
// Initialize Kafka client
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['localhost:9092'], // Replace with your broker addresses
});
// Initialize Kafka admin client
const admin = kafka.admin();
const createTopic = async () => {
try {
// Connect to the Kafka broker
await admin.connect();
// Create a new topic
await admin.createTopics({
topics: [
{
topic: 'my-topic', // Name of the topic
numPartitions: 3, // Number of partitions for the topic
replicationFactor: 1, // Replication factor
},
],
});
console.log('Topic created successfully');
} catch (error) {
console.error('Error creating topic:', error);
} finally {
// Disconnect the admin client
await admin.disconnect();
}
};
createTopic();
Step 3: Kafka Producer in Node.js
The producer sends messages to a Kafka topic
const { Kafka } = require('kafkajs');
// Initialize a Kafka client
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['localhost:9092'],
});
// Initialize a producer
const producer = kafka.producer();
const produceMessage = async () => {
// Connect the producer
await producer.connect();
// Send a message to the 'my-topic' topic
await producer.send({
topic: 'my-topic',
messages: [
{ value: 'Hello KafkaJS!' },
],
});
// Disconnect the producer
await producer.disconnect();
};
produceMessage().catch(console.error);
Step 4: Kafka Consumer in Node.js
The consumer reads messages from a Kafka topic.
const { Kafka } = require('kafkajs');
// Initialize a Kafka client
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['localhost:9092'],
});
// Initialize a consumer
const consumer = kafka.consumer({ groupId: 'test-group' });
const consumeMessages = async () => {
// Connect the consumer
await consumer.connect();
// Subscribe to the 'my-topic' topic
await consumer.subscribe({ topic: 'my-topic', fromBeginning: true });
// Run the consumer and log incoming messages
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
console.log({
partition,
offset: message.offset,
value: message.value.toString(),
});
},
});
};
consumeMessages().catch(console.error);
Kafka Streams
- Introduction to Kafka Streams:
Kafka Streams is a Java library for building applications that process data in real-time. It allows you to build complex event-driven applications with minimal coding. - Stream Processing vs. Batch Processing:
Real-time processing, enabled by Kafka Streams, is crucial for applications that need immediate insights, such as fraud detection systems or live metrics dashboards. - Example Use Case:
A real-time analytics application that processes user interactions on a website. Kafka Streams can aggregate and analyze data on the fly, providing insights into user behavior.
Kafka Connect
- Overview of Kafka Connect:
Kafka Connect is a tool for streaming data between Kafka and other data systems. It simplifies the process of integrating Kafka with databases, key-value stores, search indexes, and more. - Connectors:
Source connectors ingest data from external systems into Kafka, while sink connectors write data from Kafka to external systems. - Example Integration:
A source connector might stream data from a MySQL database into Kafka, while a sink connector writes that data to Elasticsearch for full-text search capabilities.
Monitoring and Management
- Monitoring Kafka:
Use tools like Prometheus and Grafana to monitor Kafka’s performance metrics. Monitoring ensures that your Kafka cluster is running smoothly and helps identify potential issues before they escalate. - Handling Failures:
Implement strategies such as increasing replication factor, enabling log compaction, and setting up alerts to handle common Kafka issues like broker failures or consumer lag. - Performance Tuning:
Optimize Kafka performance by fine-tuning partitioning strategies, adjusting replication settings, and configuring appropriate batch sizes for producers.
Conclusion
Summary of Kafka’s Impact:
Kafka has transformed the way organizations handle real-time data, enabling them to build more responsive, data-driven applications.
Further Reading
- Official Documentation:
Apache Kafka Documentation - Books:
“Kafka: The Definitive Guide” by Neha Narkhede, Gwen Shapira, and Todd Palino - Online Courses:
Courses on platforms like Udemy or Coursera that cover Kafka basics to advanced topics.


